Home Assistant 对唤醒词的处理方法
挑战
- 唤醒词必须处理得极快:唤醒词说出后,语音助手不能等 5 秒后才开始监听。
- 误报的余地很小。
- 唤醒词处理基于计算密集型的 AI 模型。
- 语音卫星硬件一般没有太多计算能力,因此唤醒词引擎需要硬件专家来优化模型,以顺利运行。
方法
为了避免受限于特定硬件,唤醒词检测是在 Home Assistant 内部进行的。语音卫星设备不断采样你房间内的当前音频以检测声音。当它检测到声音时,卫星会将音频发送到 Home Assistant,在那里检查是否说出了唤醒词并处理后续的命令。
这意味着任何能够流式传输音频的设备都可以变成语音卫星,即使它的性能不足以在本地运行唤醒词检测。它还允许我们的开发者社区在不缩小模型的情况下,尝试唤醒词模型,以便在低功耗的语音卫星设备上运行。
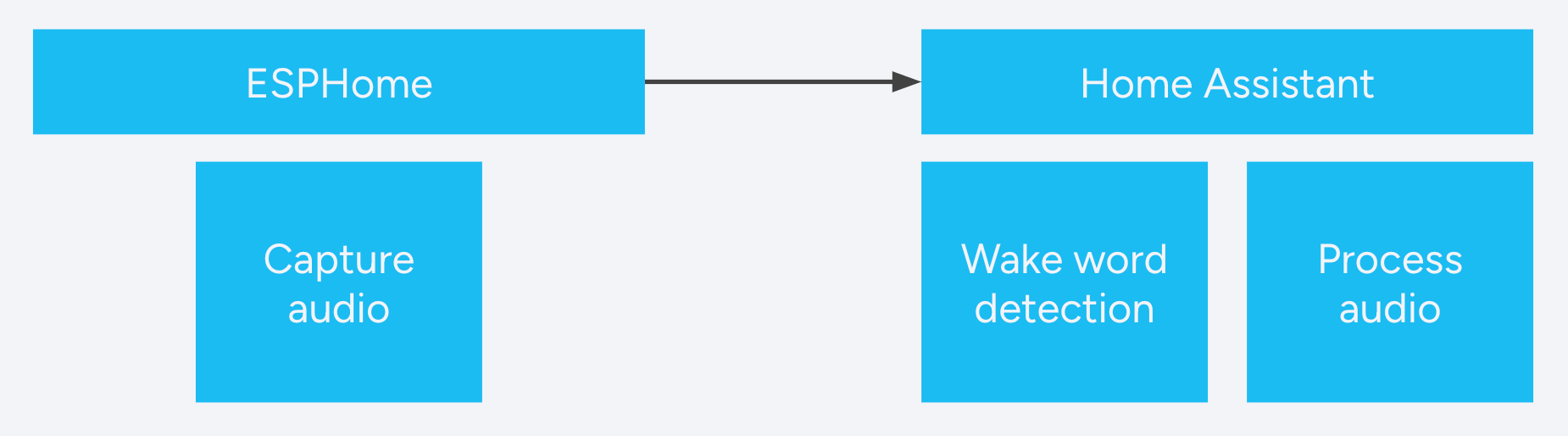 唤醒词架构的概述
唤醒词架构的概述
这种方法的缺点
-
捕获的音频质量在设备之间有所不同。配有多个麦克风和音频处理芯片的扬声器电话能非常干净地捕捉声音。而单个麦克风且没有后处理的设备?就差多了。我们通过 Home Assistant 内部的音频后处理来补偿音频质量差,用户可以使用更好的语音转文本模型来提高准确性,例如 Home Assistant Cloud中包含的那个。
-
每个卫星在流式传输音频时都需要 Home Assistant 内部的持续资源。目前,用户可以同时让 5 个语音卫星流式传输音频,而不会使 Raspberry Pi 4 超负荷。为了扩展,我们更新了 怀俄明协议
,允许用户在外部服务器上运行唤醒词检测。
关于 openWakeWord 插件
Home Assistant 的唤醒词利用了 David Scripka 的一个新项目 openWakeWord
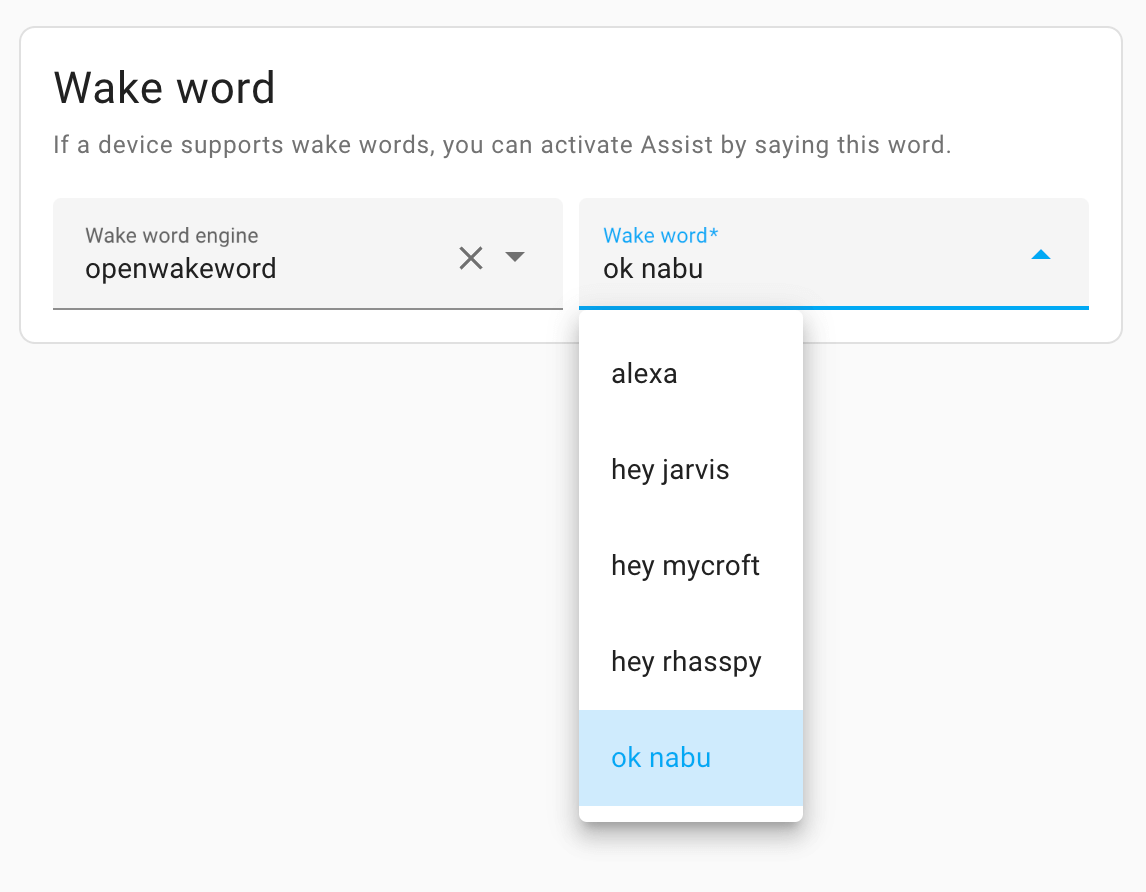 用户可以为每个配置的语音助手选择监听的唤醒词
用户可以为每个配置的语音助手选择监听的唤醒词
挑战
openWakeWord 的创建考虑了 4 个目标:
- 足够快以用于真实世界的应用。
- 足够准确以用于真实世界的应用。
- 具有简单的模型架构和推理过程。
- 对于训练新模型几乎不需要手动数据收集。
训练模型
openWakeWord 基于由 Google 训练的开源音频嵌入模型构建,并使用文本到语音系统 Piper
 openWakeWord 训练流水线的概述。
openWakeWord 训练流水线的概述。
支持的语言
OpenWakeWord 目前仅支持英语唤醒词。这是因为其他语言中不同说话者的模型仍然稀缺。随着每种语言的多说话者模型变得可用,其他语言的类似模型可以进行训练。
Docker 中的 openWakeWord
如果你不运行 Home Assistant OS,openWakeWord 也可以作为 Docker 容器
其他唤醒词引擎
Home Assistant 附带默认设置,但允许用户配置语音助手的每个部分。这同样适用于唤醒词。
你可以将其他唤醒词引擎作为集成添加,或将其作为独立程序运行,通过 怀俄明协议
 唤醒词如何集成到 Home Assistant
唤醒词如何集成到 Home Assistant
例如,我们还提供 Porcupine (v1) 唤醒词引擎。它支持 29 个唤醒词,涵盖英语、法语、西班牙语和德语。唤醒词包括 Computer、Framboise、Manzana 和 Stachelschwein。
关于设备上的唤醒词处理(microWakeWord)
microWakeWord
由于 openWakeWord 的体积太大,无法在像 S3-BOX-3 这样的低功耗设备上运行,因此 openWakeWord 在 Home Assistant 服务器上运行唤醒词检测。
在 Home Assistant 上进行唤醒词检测允许低功耗设备,如 M5 ATOM Echo 开发套件,简单地流式传输音频,并让所有处理在其他地方进行。 缺点是增加更多语音助手需要在 Home Assistant 中消耗更多的 CPU 资源,以及更多的网络流量。
引入 microWakeWord;一个基于 Google 的 Inception 神经网络
目前,有 三种模型
- okay nabu
- hey jarvis
- alexa
尝试一下!
现在,有两个简单的选项开始使用唤醒词:
- 按照 $13 语音助手 的指南进行操作。此教程使用小型 ATOM Echo,通过 openWakeWord 检测唤醒词。
- 按照设置 ESP32-S3-BOX-3 语音助手 的指南进行操作。此教程使用更大的 S3-BOX-3 设备,该设备带有显示屏。它可以通过 openWakeWord 检测唤醒词。但它也可以使用 microWakeWord 进行设备上的唤醒词检测。